📚 목차
[Next.js] TanStack Query + TanStack Virtual로 대용량 리스트 최적화하기
VitalTrip 서비스에서 몇 천개의 의료 질환 데이터를 제공하는 응급 사전 페이지를 개발하는 과정에서 무한스크롤의 한계를 경험했고, 이를 useInfiniteQuery의 캐싱 구조와 useWindowVirtualizer의 가상화 렌더링으로 개선한 사례를 공유하고자 합니다.
초기 목표는 단순했습니다.
사용자가 의료 질환 정보를 끊김 없이 탐색할 수 있도록, 데이터를 한 번에 모두 렌더링하지 않고 무한스크롤로 제공하자.
하지만 실제로 목록을 충분히 탐색한 뒤 DevTools와 React Profiler로 측정해보니, 무한스크롤만으로는 해결되지 않는 문제가 있었습니다.
무한스크롤은 데이터를 나눠 가져오는 데는 효과적이지만, 이미 렌더링된 카드 DOM을 줄여주지는 않습니다.
결과적으로 사용자가 아래로 계속 스크롤할수록 이전 카드들이 DOM에 계속 남았고, DOM 노드 수와 React 렌더링 비용이 함께 증가했습니다.
구현 배경
응급 사전 페이지는 의료 질환 정보를 카드 목록으로 제공하는 화면입니다.
데이터는 외부 의료 API 기반 의료 질환 데이터였고, 전체 항목 수는 1,016개였습니다.
각 카드에는 질환명, 요약 정보, 관련 설명 등이 포함되어 있었기 때문에 단순 텍스트 리스트보다 DOM 구조가 무거웠습니다.
처음부터 1,016개 데이터를 한 번에 렌더링하는 방식은 적절하지 않다고 판단했습니다.
이유는 명확했습니다.
- 초기 렌더링 비용 증가
- 불필요한 네트워크 요청 증가
- 사용자가 보지 않는 데이터까지 미리 렌더링
- 모바일 WebView 환경에서 스크롤 성능 저하 가능성
그래서 첫 번째 선택은 useInfiniteQuery 기반 무한스크롤이었습니다.
useInfiniteQuery 기반 무한스크롤
무한스크롤은 useInfiniteQuery로 구현했습니다.
| 역할 | 설명 |
|---|---|
useInfiniteQuery | offset 기반 데이터 요청 |
getNextPageParam | 다음 offset 계산 |
fetchNextPage | 다음 데이터 로드 |
IntersectionObserver | 목록 하단 진입 감지 |
| Query Cache | 이미 불러온 페이지 데이터 캐싱 |
기본 구조는 다음과 같았습니다.
const { data, fetchNextPage, hasNextPage, isFetchingNextPage } = useInfiniteQuery({
queryKey: ['encyclopedia'],
queryFn: ({ pageParam }) => fetchEncyclopediaPage({ offset: pageParam }),
initialPageParam: 0,
getNextPageParam: (lastPage, allPages) => {
const loaded = allPages.flatMap((p) => p.items).length;
return loaded < lastPage.total ? loaded : undefined;
},
});
const items = data?.pages.flatMap((page) => page.items) ?? [];렌더링은 일반적인 map 구조였습니다.
return (
<main>
{items.map((item) => (
<EncyclopediaCard key={item.id} item={item} />
))}
<div ref={observerRef} />
</main>
);목록 하단에는 IntersectionObserver를 연결한 sentinel 요소를 두었습니다.
useEffect(() => {
if (!observerRef.current) return;
const observer = new IntersectionObserver(([entry]) => {
if (entry.isIntersecting && hasNextPage && !isFetchingNextPage) {
fetchNextPage();
}
});
observer.observe(observerRef.current);
return () => observer.disconnect();
}, [fetchNextPage, hasNextPage, isFetchingNextPage]);이 방식은 데이터 로딩 관점에서는 잘 동작했습니다.
사용자가 하단에 도달하면 다음 페이지를 가져왔고, 이전 데이터는 TanStack Query 캐시에 유지되었습니다.
문제는 렌더링이었습니다.
무한스크롤만으로 부족했던 이유
무한스크롤은 데이터를 점진적으로 가져오는 전략입니다.
하지만 이미 가져온 데이터를 DOM에서 제거하지는 않습니다.
즉, 아래 구조에서는 items가 늘어날수록 렌더링되는 카드도 계속 늘어납니다.
{
items.map((item) => <EncyclopediaCard key={item.id} item={item} />);
}화면에 실제로 보이는 카드는 10개 안팎인데도, 스크롤할수록 100개, 900개씩 카드가 DOM에 그대로 쌓이고 브라우저는 지나간 카드 DOM까지 계속 관리해야 합니다.
이 구조에서는 데이터가 늘어날수록 다음 비용이 선형적으로 증가합니다.
- React reconciliation 비용
- DOM 노드 관리 비용
- layout 계산 비용
- paint 비용
- 스크롤 중 브라우저 메인 스레드 부담
즉, 문제는 네트워크가 아니라 렌더링이었습니다.
성능 측정
먼저 실제 DOM이 얼마나 누적되는지 확인했습니다.
전체 DOM 노드 수는 DevTools Console에서 측정했습니다.

가상화 전에는, 전체 DOM 노드가 10,103개까지 증가했습니다.
또한, 실제 렌더링된 카드 수는 916개 항목이 모두 DOM에 렌더링된 상태인 것을 확인할 수 있었습니다.
Chrome devtools의 React Profiler와 Performance 탭에서도 렌더링 비용이 점점 증가하는 것을 확인할 수 있었습니다.
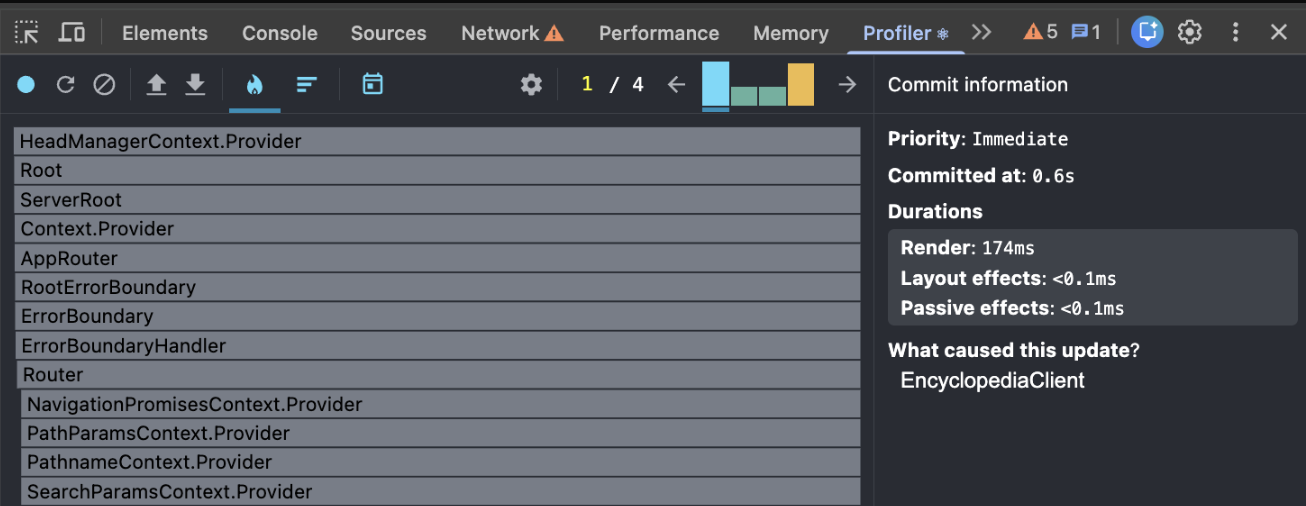
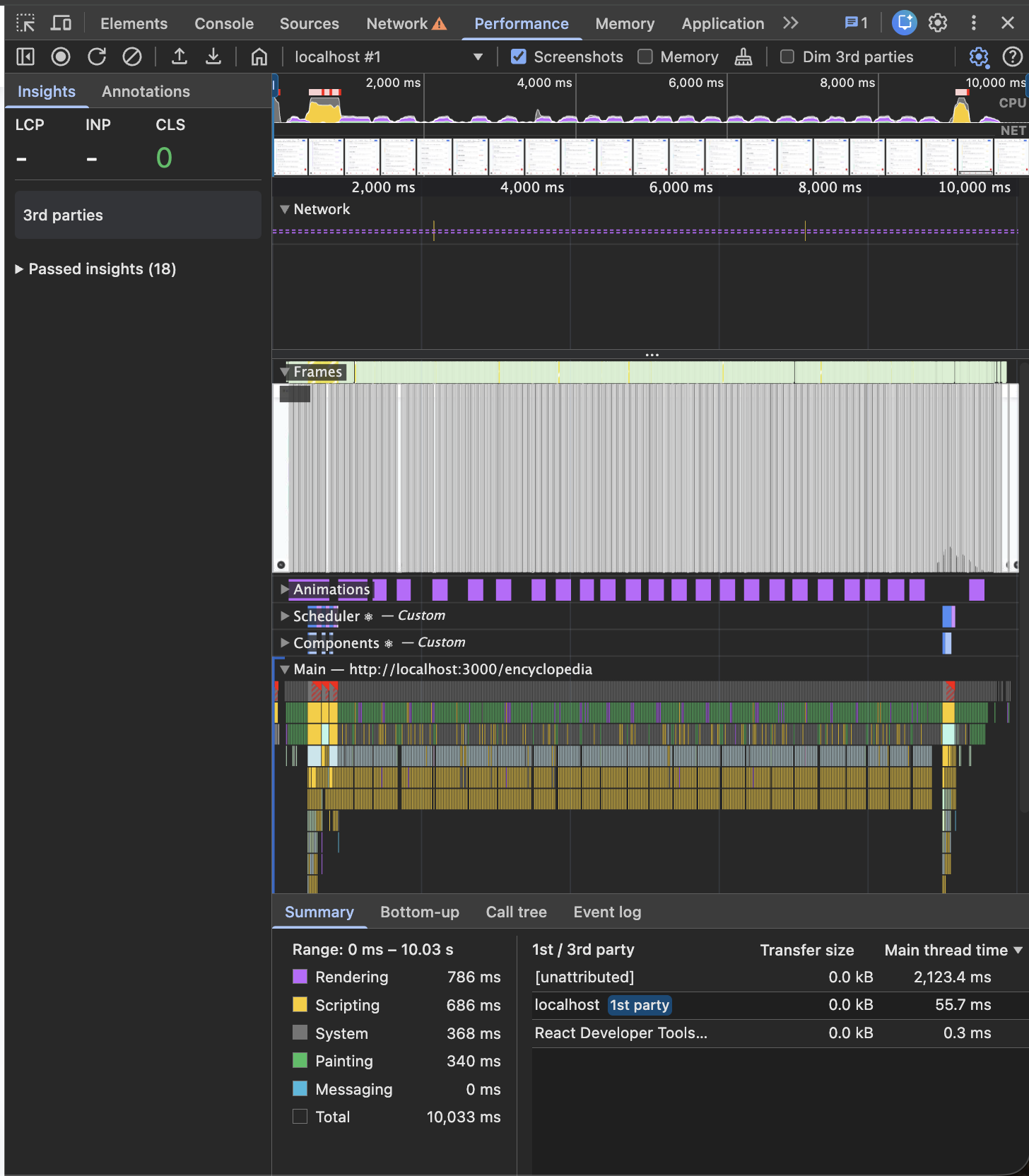
| 지표 | Before |
|---|---|
| 전체 DOM 노드 수 | 10,103개 |
| 렌더링된 카드 수 | 916개 |
| React commit render | 174ms |
| Performance Rendering | 786ms |
| Performance Painting | 340ms |
특히 React Profiler 기준 selected commit render 시간이 174ms까지 나타났습니다.
이제 목표는 명확해졌습니다.
useInfiniteQuery로 데이터는 계속 페이지 단위로 가져오되, DOM에는 현재 화면 주변 카드만 유지하자.
해결 방향: useInfiniteQuery + useWindowVirtualizer
문제를 해결하기 위해 기존 useInfiniteQuery 구조는 유지하면서 두 가지를 개선했습니다.
- 렌더링 계층:
@tanstack/react-virtual의useWindowVirtualizer추가 - 검색 지원: queryKey에 검색어를 포함해 검색별 캐싱 구조로 확장
- 하단 감지: IntersectionObserver → window scroll 이벤트로 교체
- 초기 데이터: SSR fetch 결과를 initialData로 연결해 첫 화면 네트워크 요청 제거
각 도구의 역할은 분리되어 있습니다.
| 도구 | 역할 |
|---|---|
@tanstack/react-query | 서버 데이터 fetching, 페이지별 캐싱 |
useInfiniteQuery | offset 기반 무한 로딩, 검색어별 캐시 |
@tanstack/react-virtual | 대용량 리스트 가상화 |
useWindowVirtualizer | window 스크롤 기준 viewport 렌더링 |
왜 useWindowVirtualizer를 선택했을까?
TanStack Virtual에는 일반적으로 두 가지 방식이 있습니다.
첫 번째는 특정 컨테이너 내부 스크롤을 기준으로 하는 방식입니다.
useVirtualizer({
getScrollElement: () => parentRef.current,
...
});두 번째는 브라우저 window 스크롤을 기준으로 하는 방식입니다.
useWindowVirtualizer({
...
});VitalTrip 서비스 내 응급 사전 페이지는 별도의 고정 높이 스크롤 컨테이너가 아니라, 페이지 전체가 자연스럽게 스크롤되는 구조였습니다.
<Header />
<SearchSection />
<CategoryFilter />
<EncyclopediaList />
<Footer />이 구조에서 별도 스크롤 박스를 만들면 UX가 어색해질 수 있습니다.
특히 모바일 앱에서는 WebView로 Next.js 서비스를 재사용하고 있었기 때문에, 이중 스크롤 구조는 피하고 싶었습니다.
그래서 기존 window 스크롤 UX는 유지하면서 리스트 영역만 가상화할 수 있는 useWindowVirtualizer를 선택했습니다.
useWindowVirtualizer 적용
기존 무한스크롤 로직을 개선하고, 렌더링 계층에 useWindowVirtualizer를 적용했습니다.
이 페이지의 데이터 흐름은 다음과 같습니다.
SSR: fetchEncyclopedia() → initialItems, total 확보
↓
useInfiniteQuery initialData로 클라이언트 상태 초기화
↓
검색어 변경 시 queryKey 변경 → 자동 재요청 및 캐싱
↓
스크롤 하단 접근 시 fetchNextPage() 호출
↓
카테고리 필터 적용 (useMemo)
↓
useWindowVirtualizer로 viewport 주변 카드만 렌더링SSR 초기 데이터와 initialData 연결
Next.js SSR로 초기 데이터를 미리 불러와 useInfiniteQuery의 initialData로 연결했습니다.
// app/encyclopedia/page.tsx
export default async function EncyclopediaPage() {
const { total, items } = await fetchEncyclopedia();
return <EncyclopediaClient initialItems={items} total={total} />;
}const { data, fetchNextPage, hasNextPage, isFetchingNextPage, isPending } = useInfiniteQuery({
queryKey: ['encyclopedia', debouncedQuery],
queryFn: ({ pageParam }) =>
fetchEncyclopediaPage({
search: debouncedQuery || undefined,
offset: pageParam,
}),
initialPageParam: 0,
getNextPageParam: (lastPage, allPages) => {
const loaded = allPages.flatMap((p) => p.items).length;
return loaded < lastPage.total ? loaded : undefined;
},
initialData:
debouncedQuery === ''
? { pages: [{ total: initialTotal, items: initialItems }], pageParams: [0] }
: undefined,
staleTime: 1000 * 60 * 5,
});검색어가 없는 초기 상태에서는 SSR 데이터를 그대로 사용해 첫 화면 진입 시 추가 네트워크 요청이 발생하지 않습니다. staleTime: 5분으로 동일 검색어는 캐시에서 즉시 반환합니다.
검색어 debounce와 queryKey 기반 캐싱
입력값을 300ms debounce 후 queryKey에 반영합니다. 검색어가 바뀌면 TanStack Query가 자동으로 새 데이터를 요청하고, 이전에 검색한 키워드는 캐시에서 즉시 반환합니다.
// 300ms debounce
useEffect(() => {
const timer = setTimeout(() => setDebouncedQuery(query.trim()), 300);
return () => clearTimeout(timer);
}, [query]);
// 검색어 변경 시 스크롤 초기화
useEffect(() => {
window.scrollTo(0, 0);
}, [debouncedQuery]);queryKey: ['encyclopedia', debouncedQuery];window scroll 기반 추가 로딩
useWindowVirtualizer가 window 스크롤을 사용하기 때문에 IntersectionObserver 대신 scroll 이벤트로 교체했습니다. 하단 400px 전에 미리 다음 페이지를 요청해 로딩 지연을 줄입니다.
useEffect(() => {
const handleScroll = () => {
if (isFetchingNextPage || !hasNextPage) return;
const scrollY = window.scrollY;
const windowHeight = window.innerHeight;
const docHeight = document.documentElement.scrollHeight;
if (docHeight - scrollY - windowHeight < 400) fetchNextPage();
};
window.addEventListener('scroll', handleScroll, { passive: true });
return () => window.removeEventListener('scroll', handleScroll);
}, [isFetchingNextPage, hasNextPage, fetchNextPage]);카테고리 필터링
검색 결과 또는 초기 목록에서 카테고리 필터를 적용했습니다.
const items = data?.pages.flatMap((p) => p.items) ?? [];
const filtered = useMemo(() => {
if (category === 'all') return items;
return items.filter((item) => getCategory(item.categories) === category);
}, [items, category]);가상화의 대상은 전체 items가 아니라, 최종적으로 화면에 보여줄 filtered 배열입니다.
즉, 검색과 카테고리 필터를 거친 결과에 대해서만 가상화 렌더링이 적용됩니다.
useWindowVirtualizer 적용
렌더링 최적화의 핵심은 useWindowVirtualizer입니다.
const listRef = useRef<HTMLDivElement>(null);
const virtualizer = useWindowVirtualizer({
count: filtered.length,
estimateSize: () => 80,
overscan: 5,
paddingEnd: 96,
scrollMargin: listRef.current?.offsetTop ?? 0,
});각 옵션의 역할은 다음과 같습니다.
| 옵션 | 역할 |
|---|---|
count | 가상화 대상 아이템 개수 |
estimateSize | 카드 1개의 예상 높이 |
overscan | viewport 밖에 미리 렌더링할 항목 수 |
paddingEnd | 리스트 하단 여백 |
scrollMargin | 리스트가 페이지 상단에서 떨어진 거리 보정 |
이 코드에서 중요한 부분은 scrollMargin입니다.
useWindowVirtualizer는 window 스크롤을 기준으로 아이템 위치를 계산합니다.
그런데 실제 리스트는 페이지 최상단에서 바로 시작하지 않습니다.
상단에는 헤더, 검색 영역, 카테고리 필터, 결과 카운터가 있습니다.
리스트 시작 지점의 offsetTop을 scrollMargin으로 전달해, window 기준 스크롤 위치와 리스트 내부 아이템 위치 계산을 맞춥니다.
단, listRef.current?.offsetTop ?? 0 방식은 한 가지 함정이 있습니다.
React에서 ref는 DOM commit 이후에 설정됩니다. 따라서 useWindowVirtualizer가 처음 실행되는 시점에는 listRef.current가 아직 null이고, scrollMargin은 0으로 초기화됩니다.
이후 스크롤이나 상태 변경으로 리렌더가 발생하면 실제 offsetTop 값으로 보정되지만, 초기 렌더부터 정확한 값을 보장하려면 useLayoutEffect로 마운트 직후 측정하는 방식이 더 안전합니다.
const listRef = useRef<HTMLDivElement>(null);
const [scrollMargin, setScrollMargin] = useState(0);
useLayoutEffect(() => {
setScrollMargin(listRef.current?.offsetTop ?? 0);
}, []);
const virtualizer = useWindowVirtualizer({
count: filtered.length,
estimateSize: () => 80,
overscan: 5,
paddingEnd: 96,
scrollMargin,
});useLayoutEffect는 DOM이 paint되기 전 동기적으로 실행되므로, 첫 렌더부터 올바른 offsetTop을 virtualizer에 전달할 수 있습니다.
가상화 리스트 렌더링
기존 방식은 전체 filtered 배열을 모두 렌더링하는 구조였습니다.
{
filtered.map((item) => <EncyclopediaCard key={item.id} item={item} />);
}가상화 적용 후에는 virtualizer.getVirtualItems()가 반환하는 항목만 렌더링합니다.
<div
ref={listRef}
style={{
height: virtualizer.getTotalSize(),
position: 'relative',
}}
>
{virtualizer.getVirtualItems().map((virtualItem) => {
const item = filtered[virtualItem.index];
const categoryLabel = t(`encyclopedia.categories.${getCategory(item.categories)}`);
return (
<div
key={virtualItem.key}
data-index={virtualItem.index}
ref={virtualizer.measureElement}
style={{
position: 'absolute',
top: 0,
left: 0,
width: '100%',
transform: `translateY(${virtualItem.start - virtualizer.options.scrollMargin}px)`,
}}
>
<EncyclopediaCard item={item} categoryLabel={categoryLabel} />
</div>
);
})}
</div>바깥 div는 전체 리스트 높이를 담당합니다.
height: virtualizer.getTotalSize();그리고 실제 카드들은 absolute로 배치합니다.
position: 'absolute';각 카드의 세로 위치는 virtualizer가 계산한 start 값을 기준으로 이동시킵니다.
transform: `translateY(${virtualItem.start - virtualizer.options.scrollMargin}px)`;여기서 scrollMargin을 빼는 이유는, 리스트가 페이지 중간에서 시작하기 때문입니다.
useWindowVirtualizer가 window 전체 스크롤 기준으로 위치를 계산하므로, 실제 리스트 내부 좌표계에 맞추려면 리스트 시작 위치만큼 보정해야 합니다.
동적 높이 대응
카드는 텍스트 길이나 카테고리 라벨에 따라 높이가 달라질 수 있습니다.
따라서 각 카드 wrapper에 measureElement와 data-index를 함께 연결했습니다.
data-index={virtualItem.index}
ref={virtualizer.measureElement}measureElement는 ResizeObserver로 DOM 요소의 실제 크기를 측정합니다.
이때 data-index 속성을 읽어 측정 결과를 어떤 아이템에 반영할지 식별합니다.
data-index가 없으면 measureElement가 크기를 측정해도 어떤 아이템의 높이인지 알 수 없어 위치 계산이 틀어집니다.
초기에는 estimateSize: () => 80으로 예상 높이를 사용하고, 실제 렌더링된 뒤에는 measureElement가 실제 높이를 측정합니다.
이렇게 하면 카드 높이가 완전히 고정되어 있지 않아도 스크롤 위치 계산의 정확도를 높일 수 있습니다.
적용 후 결과
위 영상과 같이 가상화 적용 후에는 현재 보이는 카드 주변만 DOM에 렌더링되고, 스크롤할 때마다 필요한 카드가 동적으로 추가/제거되는 것을 확인할 수 있습니다.
가상화 적용 후 동일하게 DOM 노드 수를 측정해보니, 가상화 전 10,103개였던 전체 DOM 노드 수가 316개로 줄어든 것을 확인할 수 있었습니다.

기존에는 916개 카드가 DOM에 남아 있었지만, 가상화 후에는 viewport와 overscan 영역의 카드만 DOM에 유지되었습니다.
Chrome Devtools에서 React Profiler와 Performance에서도 개선이 확인되었습니다.
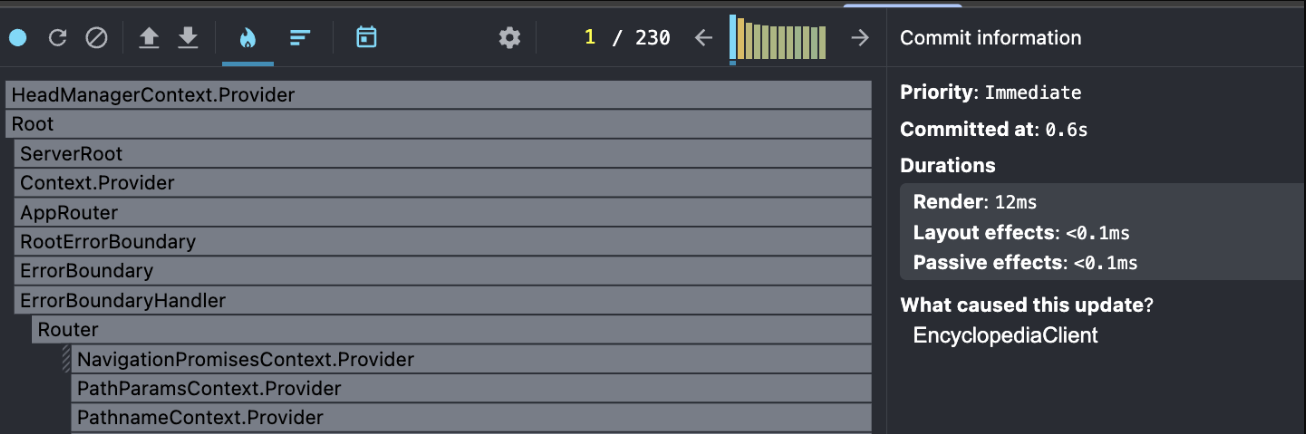
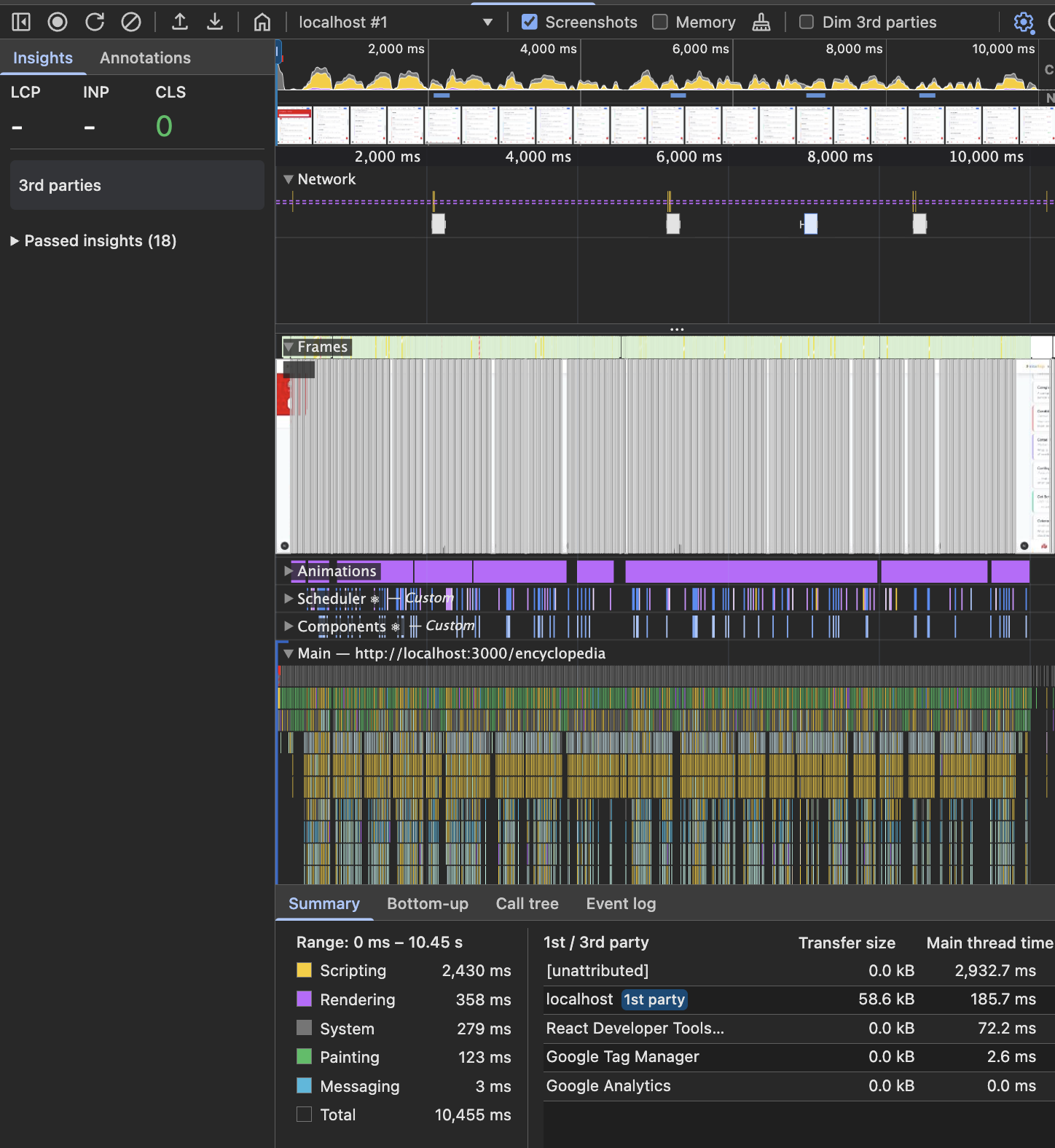
| 지표 | Before | After | 개선 |
|---|---|---|---|
| 전체 DOM 노드 수 | 10,103개 | 316개 | 96.9% 감소 |
| 렌더링된 카드 수 | 916개 | 10개 | 98.9% 감소 |
| React commit render | 174ms | 12ms | 93.1% 감소 |
| Performance Rendering | 786ms | 358ms | 54.5% 감소 |
| Performance Painting | 340ms | 123ms | 63.8% 감소 |
이번 최적화에서 가장 중요한 지표는 전체 DOM 노드 수와 React commit render 시간이었습니다.
DOM 노드 수: 10,103개 → 316개
React commit render: 174ms → 12ms
목록 데이터는 계속 유지하면서도, 실제 DOM 렌더링 대상을 viewport 중심으로 제한한 결과입니다.
마무리
무한스크롤은 네트워크 비용을 줄이는 데는 효과적이지만, 렌더링 비용을 줄이지는 않습니다.
사용자가 목록을 계속 탐색할수록 DOM에 카드가 누적되고, 브라우저는 보이지 않는 영역까지 관리해야 합니다.
useWindowVirtualizer는 이 문제를 viewport 기준 렌더링으로 해결합니다.
전체 데이터는 useInfiniteQuery의 pages 배열에 유지하되, 실제 DOM에는 현재 보이는 영역과 그 주변(overscan)만 렌더링합니다.
useInfiniteQuery와 useWindowVirtualizer의 역할은 명확하게 분리되어 있습니다.
useInfiniteQuery: 데이터를 언제, 어떻게 가져올지 (fetching, caching)useWindowVirtualizer: 가져온 데이터를 어떻게 보여줄지 (rendering)
두 가지가 분리되어 있기 때문에, 검색어가 바뀌어도 이전 결과는 캐시에 남고, 스크롤 위치가 바뀌어도 데이터는 그대로 유지됩니다.
이번 구현을 통해 체감한 몇 가지를 정리합니다.
useWindowVirtualizer가 적합한 상황
- 리스트가 별도 스크롤 컨테이너 없이 페이지 전체 스크롤로 동작하는 경우
- 모바일 WebView처럼 이중 스크롤이 부자연스러운 환경
- 카드 높이가 고정되지 않아 동적으로 측정이 필요한 경우
주의할 점
- scrollMargin을 정확히 설정하지 않으면 아이템 위치가 어긋납니다. 리스트 상단에 헤더나 필터 영역이 있다면 반드시 offsetTop을 전달해야 합니다.
- estimateSize는 초기 레이아웃에만 사용됩니다. 실제 높이는 measureElement가 렌더링 후 측정하므로, 카드마다 높이 차이가 크다면 초기 스크롤 위치 계산이 부정확할 수 있습니다.
- initialData와 staleTime을 함께 설정하지 않으면 마운트 직후 불필요한 배경 재요청이 발생합니다.
대용량 리스트에서 무한스크롤만으로 성능이 충분하지 않다면, useInfiniteQuery로 데이터 흐름을 관리하면서 useWindowVirtualizer로 렌더링을 제한하는 조합이 실용적인 선택이 될 수 있습니다.