📚 목차
[Backend] NestJS 서버에 K6 부하테스트와 Prometheus와 Grafana로 모니터링 구축하기
VitalTrip은 여행 중 응급 상황이 발생했을 때 사용자가 빠르게 도움을 받을 수 있도록 돕는 여행자 응급처치 서비스입니다.
백엔드는 NestJS, Prisma, MySQL 기반으로 구성했고, 인증·사용자 정보·응급 상황 처리와 같은 핵심 API를 제공합니다.
처음에는 기능 구현과 API 정상 동작에 집중했습니다. 로컬과 개발 서버에서 요청이 잘 처리되고, 테스트도 통과했기 때문에 어느 정도 안정적으로 동작한다고 생각했습니다. 하지만 실제 서비스는 “요청이 성공한다”만으로 충분하지 않습니다.
사용자가 동시에 몰렸을 때도 빠르게 응답하는지, 특정 API만 유난히 느린지, DB 조회가 문제인지, CPU를 많이 쓰는 로직이 문제인지, 에러가 발생하지 않더라도 응답 시간이 계속 나빠지고 있는지 알 수 있어야 합니다.
이 문제의식을 가지고 k6로 부하테스트를 진행했습니다.
테스트 환경
- 서버: AWS EC2 + Docker
- 백엔드: NestJS + Prisma + MySQL
- 부하테스트: k6
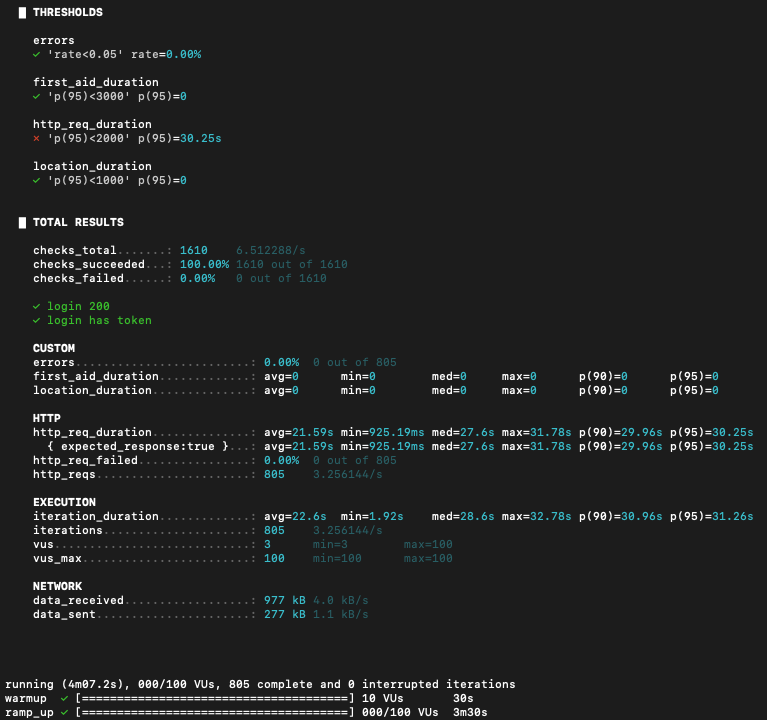
- 시나리오: 100 VUs, 워밍업 30초 → 최대 100명 2분 유지부하테스트 결과, 최초 상태의 로그인 관련 API는 다음과 같은 성능을 보였습니다.
| 단계 | p95 | avg | TPS |
|---|---|---|---|
| Before | 30.52s | 21.9s | 3.23/s |
에러율은 0%였지만, p95 응답 시간이 30초를 넘었습니다. 즉, 서버는 요청을 실패시키지는 않았지만 사용자가 기다리기 어려운 수준으로 느려지고 있었습니다.
여기서 중요한 질문이 생겼습니다.
“느리다”는 사실은 알겠는데, 어디가 느린 걸까?
k6는 외부에서 본 결과를 알려줍니다. 평균 응답 시간, p95, TPS, 에러율처럼 사용자가 체감하는 지표를 확인하기에 좋습니다. 하지만 서버 내부에서 무슨 일이 일어나는지는 별도의 관찰 장치가 필요합니다.
그래서 NestJS 서버에 Prometheus와 Grafana 기반 모니터링을 구축했습니다.
모니터링이란 무엇인가
모니터링은 서버가 지금 어떤 상태인지 숫자로 관찰하는 일입니다.
단순히 서버가 켜져 있는지 확인하는 것을 넘어, 다음과 같은 질문에 답할 수 있어야 합니다.
- 현재 초당 요청 수는 얼마나 되는가?
- 어떤 API의 응답 시간이 가장 느린가?
- p95 응답 시간은 부하가 증가할 때 어떻게 변하는가?
- 4xx, 5xx 에러 비율은 증가하고 있는가?
- 메모리 사용량이나 CPU 사용량이 계속 증가하고 있는가?
- 배포 이후 특정 지표가 나빠졌는가?
기능 테스트는 “정답을 반환하는가”를 확인합니다. 반면 모니터링은 “운영 중에도 건강하게 동작하는가”를 확인합니다.
예를 들어 로그인 API가 정상적으로 200 응답을 반환하더라도, p95 응답 시간이 30초라면 실제 사용자 경험은 실패에 가깝습니다. 이런 문제는 단순 성공/실패 로그만으로는 발견하기 어렵습니다.
그래서 운영 가능한 백엔드 서버를 만들려면 로그, 메트릭, 알림을 통해 시스템 상태를 계속 관찰할 수 있어야 합니다.
왜 Prometheus와 Grafana를 사용했나
모니터링 도구는 다양합니다. AWS CloudWatch, Datadog, New Relic, Sentry, OpenTelemetry 기반 구성 등 여러 선택지가 있습니다.
그중 이번에는 Prometheus와 Grafana를 선택했습니다.
이유는 명확했습니다.
첫째, Prometheus는 백엔드 서버가 직접 노출하는 메트릭을 주기적으로 수집하기 좋습니다. NestJS 서버에 /metrics 엔드포인트를 만들고, Prometheus가 해당 엔드포인트를 일정 간격으로 가져가도록 구성할 수 있습니다.
둘째, Grafana는 Prometheus에 쌓인 시계열 데이터를 대시보드로 시각화하기 좋습니다. 단순 숫자보다 시간에 따른 변화, API별 응답 시간 차이, 부하테스트 중 병목 구간을 훨씬 빠르게 파악할 수 있습니다.
셋째, 로컬 Docker Compose 환경부터 EC2 배포 환경까지 비교적 간단하게 구성할 수 있습니다. 실제 프로덕션 수준에서는 보안, 보관 기간, 알림 정책 등을 더 신중히 설계해야 하지만, 개인 프로젝트나 팀 프로젝트에서 모니터링을 학습하고 적용하기에 좋은 조합이었습니다.
Prometheus란 무엇인가
Prometheus는 메트릭을 수집하고 저장하는 오픈소스 모니터링 시스템입니다.
핵심은 “시간에 따라 변하는 숫자 데이터”를 저장한다는 점입니다. 예를 들어 다음과 같은 값들이 모두 메트릭이 될 수 있습니다.
http_requests_total{method="POST", route="/auth/login", status="201"} 1200
http_request_duration_seconds_bucket{route="/auth/login", le="0.5"} 830
process_cpu_user_seconds_total 42.1
nodejs_eventloop_lag_seconds 0.012Prometheus는 이런 데이터를 시계열 데이터로 저장합니다. 시계열 데이터란 특정 시점의 값이 시간 순서대로 쌓이는 데이터입니다.
예를 들어 “로그인 API p95 응답 시간”이라는 지표가 있다면, 한 번의 숫자만 보는 것이 아니라 10:00에는 300ms, 10:05에는 800ms, 10:10에는 5s처럼 시간 흐름에 따른 변화를 볼 수 있습니다.
Prometheus의 중요한 특징은 Pull 방식입니다.
일반적으로 애플리케이션이 Prometheus로 데이터를 직접 밀어 넣는 것이 아니라, 애플리케이션이 /metrics 같은 엔드포인트에 메트릭을 노출하고 Prometheus가 주기적으로 가져갑니다.
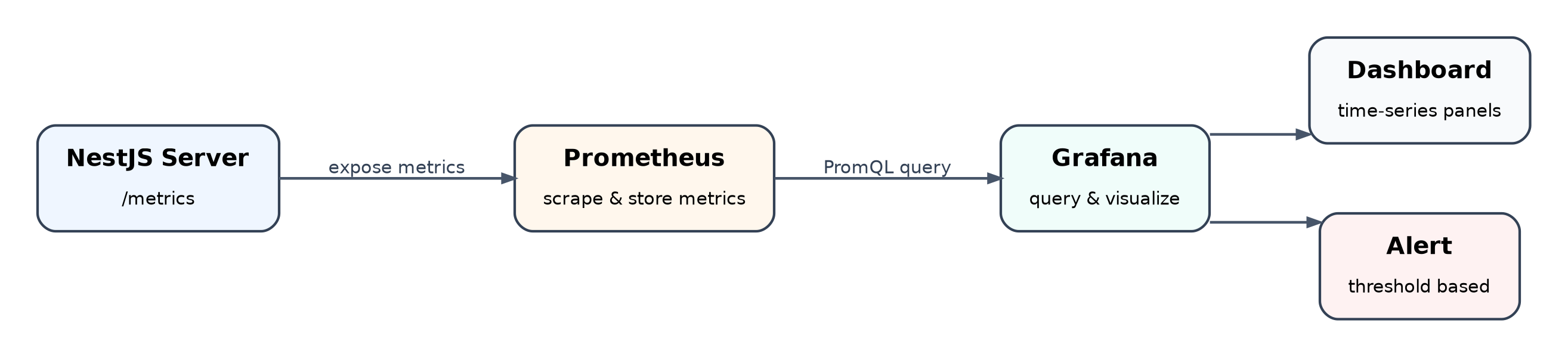
이 구조 덕분에 애플리케이션 입장에서는 메트릭을 노출하기만 하면 되고, 수집 주기와 저장은 Prometheus가 담당합니다.
Grafana란 무엇인가
Grafana는 Prometheus 같은 데이터 소스에 저장된 메트릭을 시각화하는 도구입니다.
Prometheus가 데이터를 수집하고 저장한다면, Grafana는 그 데이터를 사람이 이해하기 쉬운 형태로 보여줍니다.
예를 들어 Prometheus에 다음과 같은 데이터가 쌓여 있다고 해도 숫자만 보면 해석하기 어렵습니다.
http_request_duration_seconds_bucket{le="0.1"}
http_request_duration_seconds_bucket{le="0.5"}
http_request_duration_seconds_bucket{le="1"}
http_request_duration_seconds_bucket{le="5"}Grafana에서는 이를 다음과 같은 패널로 구성할 수 있습니다.
- API별 p95 응답 시간
- 초당 요청 수
- 상태 코드별 요청 수
- 에러율
- CPU 사용량
- 메모리 사용량
- Node.js 이벤트 루프 지연
- 배포 전후 성능 변화
즉, Grafana는 “숫자”를 “판단 가능한 화면”으로 바꿔주는 역할을 합니다.
구축한 모니터링 구조
이번 프로젝트에서는 다음과 같은 구조로 모니터링을 구성했습니다.
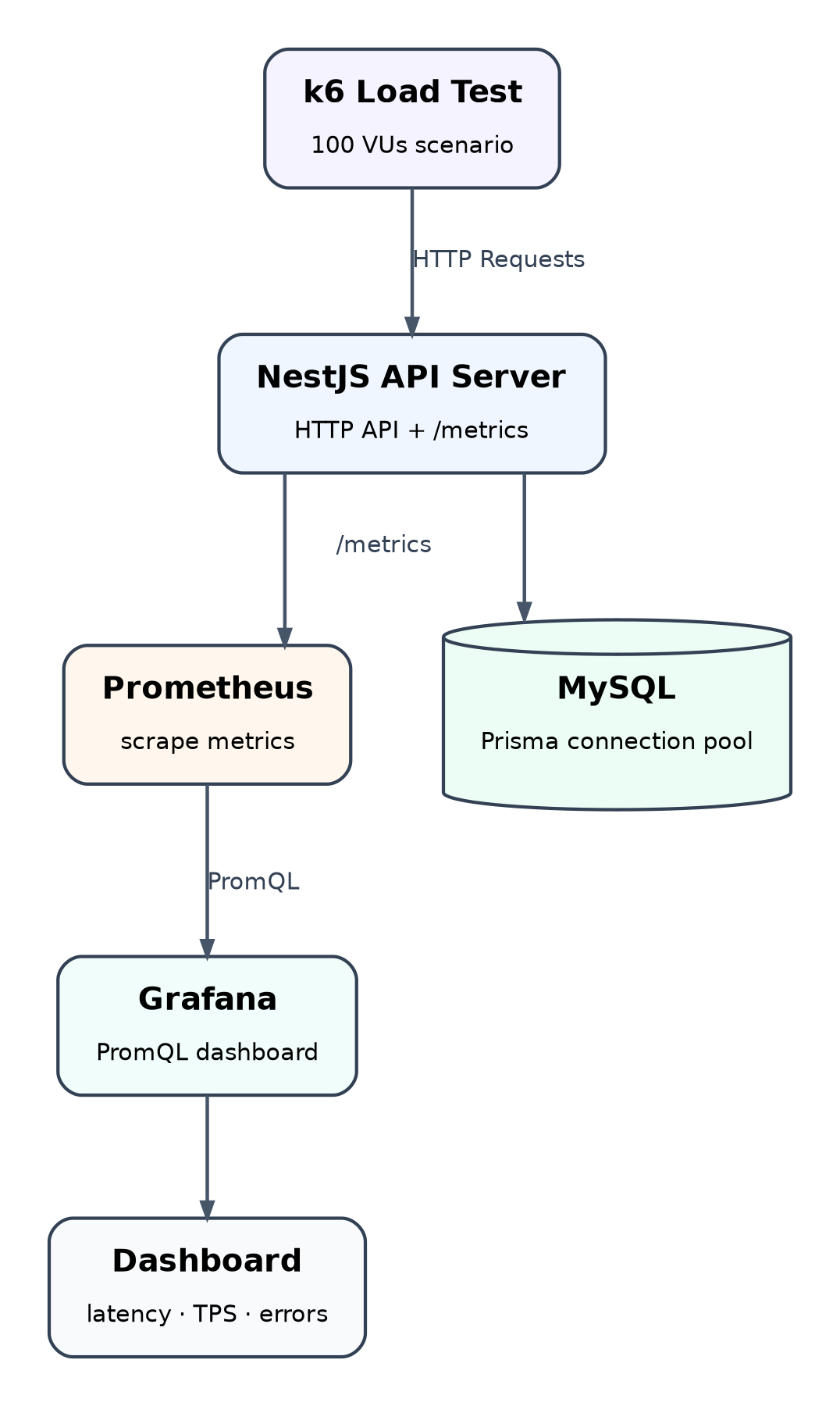
전체 흐름은 단순합니다.
- k6가 NestJS 서버에 부하를 발생시킵니다.
- NestJS 서버는 요청 수, 응답 시간, 상태 코드 등의 메트릭을
/metrics로 노출합니다. - Prometheus는 일정 주기로
/metrics를 scrape합니다. - Grafana는 Prometheus를 데이터 소스로 연결해 대시보드를 구성합니다.
- 부하테스트 중 Grafana를 보면서 어떤 지표가 나빠지는지 확인합니다.
여기서 핵심은 k6와 Grafana의 역할이 다르다는 점입니다.
k6는 외부 사용자의 관점에서 서버 성능을 측정합니다. Grafana는 서버 내부 지표를 시간 흐름에 따라 관찰합니다.
둘을 함께 사용하면 “사용자가 느리게 느낀 시점”과 “서버 내부에서 지표가 나빠진 시점”을 연결해서 볼 수 있습니다.
NestJS에서 메트릭 엔드포인트 만들기
NestJS에서는 prom-client 또는 NestJS용 Prometheus 모듈을 사용해 메트릭을 노출할 수 있습니다. 아래 코드는 구조를 설명하기 위한 예시입니다.
npm install @willsoto/nestjs-prometheus prom-clientAppModule에 Prometheus 모듈을 등록합니다.
import { Module } from '@nestjs/common';
import { PrometheusModule } from '@willsoto/nestjs-prometheus';
@Module({
imports: [
PrometheusModule.register({
path: '/metrics',
defaultMetrics: {
enabled: true,
},
}),
],
})
export class AppModule {}이렇게 하면 기본적인 Node.js 프로세스 메트릭을 수집할 수 있습니다. 예를 들어 메모리 사용량, CPU 사용 시간, 이벤트 루프 관련 지표 등을 확인할 수 있습니다.
하지만 백엔드 API를 제대로 관찰하려면 비즈니스 요청에 대한 HTTP 메트릭도 필요합니다.
대표적으로 다음 지표를 추가했습니다.
- HTTP 요청 수
- HTTP 응답 시간
- HTTP 상태 코드
- API route
- HTTP method
예시 인터셉터는 다음과 같습니다.
import { CallHandler, ExecutionContext, Injectable, NestInterceptor } from '@nestjs/common';
import { Request, Response } from 'express';
import { Observable } from 'rxjs';
import { finalize } from 'rxjs/operators';
import { Histogram, Counter } from 'prom-client';
const httpRequestCounter = new Counter({
name: 'http_requests_total',
help: 'Total number of HTTP requests',
labelNames: ['method', 'route', 'status_code'],
});
const httpRequestDuration = new Histogram({
name: 'http_request_duration_seconds',
help: 'HTTP request duration in seconds',
labelNames: ['method', 'route', 'status_code'],
buckets: [0.05, 0.1, 0.3, 0.5, 1, 3, 5, 10, 30],
});
@Injectable()
export class MetricsInterceptor implements NestInterceptor {
intercept(context: ExecutionContext, next: CallHandler): Observable<unknown> {
const http = context.switchToHttp();
const request = http.getRequest<Request>();
const response = http.getResponse<Response>();
const method = request.method;
const route = request.route?.path ?? request.path;
const start = process.hrtime.bigint();
return next.handle().pipe(
finalize(() => {
const statusCode = String(response.statusCode);
const duration = Number(process.hrtime.bigint() - start) / 1_000_000_000;
httpRequestCounter.inc({
method,
route,
status_code: statusCode,
});
httpRequestDuration.observe(
{
method,
route,
status_code: statusCode,
},
duration,
);
}),
);
}
}이후 전역 인터셉터로 등록하면 각 요청이 처리될 때마다 메트릭이 기록됩니다.
import { Module } from '@nestjs/common';
import { APP_INTERCEPTOR } from '@nestjs/core';
@Module({
providers: [
{
provide: APP_INTERCEPTOR,
useClass: MetricsInterceptor,
},
],
})
export class AppModule {}주의할 점은 route label입니다. /users/1, /users/2처럼 실제 path를 그대로 label로 넣으면 label cardinality가 커질 수 있습니다. 가능하면 /users/:id처럼 route pattern을 사용해야 합니다.
Prometheus 설정
Prometheus는 prometheus.yml 파일을 통해 어떤 서버에서 메트릭을 가져올지 설정합니다.
scrape_configs:
- job_name: 'vitaltrip-api'
metrics_path: '/metrics'
scrape_interval: 5s
static_configs:
- targets: ['api:3000']Docker Compose로 NestJS, Prometheus, Grafana를 함께 띄운다면 다음과 같은 형태로 구성할 수 있습니다.
services:
api:
build: .
ports:
- '3000:3000'
env_file:
- .env
prometheus:
image: prom/prometheus
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
ports:
- '9090:9090'
depends_on:
- api
grafana:
image: grafana/grafana
ports:
- '3001:3000'
depends_on:
- prometheus로컬에서는 위처럼 단순히 포트를 열어도 되지만, 운영 환경에서는 /metrics를 외부에 그대로 노출하지 않는 것이 좋습니다. Prometheus만 접근할 수 있도록 내부 네트워크로 제한하거나, 보안 그룹과 리버스 프록시 정책을 통해 접근 범위를 제한해야 합니다.
EC2 호스트·컨테이너 모니터링 확장
NestJS /metrics만으로는 애플리케이션 레벨 지표만 볼 수 있습니다. 하지만 실제 운영 환경에서는 다음과 같은 질문에도 답할 수 있어야 합니다.
- EC2 서버 자체의 CPU, 메모리, 디스크 사용량은 얼마인가?
- Docker 컨테이너 각각이 리소스를 얼마나 쓰고 있는가?
- 특정 컨테이너가 메모리를 과도하게 점유하고 있지는 않은가?
애플리케이션은 정상으로 보여도, 호스트 서버의 디스크가 꽉 차거나 메모리가 부족하면 서비스는 장애가 납니다. 이를 위해 node-exporter와 cAdvisor를 추가했습니다.
확장된 모니터링 구조는 다음과 같습니다.
EC2 서버 상태 → node-exporter:9100 ┐
Docker 컨테이너 상태 → cadvisor:8080 ├→ Prometheus → Grafana
NestJS API 상태 → app:3000/metrics ┘node-exporter — EC2 호스트 메트릭 수집
node-exporter는 Linux 호스트 시스템의 하드웨어·OS 수준 메트릭을 수집하는 Prometheus 공식 exporter입니다.
/proc, /sys, /rootfs를 읽어 다음과 같은 지표를 제공합니다.
- CPU 사용률 (idle, user, system, iowait)
- 메모리 사용량 (total, available, buffers, cached)
- 디스크 I/O 및 사용량
- 네트워크 트래픽 (bytes sent/received)
- 파일 시스템 마운트 상태
node-exporter:
image: prom/node-exporter:latest
restart: always
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
command:
- '--path.procfs=/host/proc'
- '--path.rootfs=/rootfs'
- '--path.sysfs=/host/sys'
- '--collector.filesystem.mount-points-exclude=^/(sys|proc|dev|host|etc)($$|/)'/proc, /sys, /rootfs를 읽기 전용(:ro)으로 마운트합니다. 호스트를 수정하지 않고 데이터를 읽기만 하기 위해서입니다.
--collector.filesystem.mount-points-exclude 옵션은 /proc, /sys, /dev 같은 가상 파일시스템을 디스크 사용량 수집 대상에서 제외합니다. 이 경로들은 실제 파일시스템이 아니기 때문에 포함시키면 지표가 왜곡됩니다.
cAdvisor — Docker 컨테이너별 메트릭 수집
cAdvisor(Container Advisor)는 Docker 컨테이너별 리소스 사용량을 수집하는 Google 오픈소스 도구입니다.
node-exporter가 호스트 전체를 관찰한다면, cAdvisor는 각 컨테이너를 개별적으로 관찰합니다.
- 컨테이너별 CPU 사용률
- 컨테이너별 메모리 사용량
- 컨테이너별 네트워크 I/O
- 컨테이너별 디스크 I/O
cadvisor:
image: gcr.io/cadvisor/cadvisor:latest
restart: always
privileged: true
volumes:
- /:/rootfs:ro
- /var/run:/var/run:ro
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
- /dev/disk/:/dev/disk:roprivileged: true가 필요한 이유는 cAdvisor가 Docker 데몬 소켓과 시스템 파일에 직접 접근해야 하기 때문입니다. 호스트의 컨테이너 런타임 정보를 읽으려면 이 권한이 필요합니다.
Prometheus scrape job 추가
node-exporter와 cAdvisor가 각각 9100, 8080 포트에서 메트릭을 노출하므로, prometheus.yml에 scrape job을 추가합니다.
scrape_configs:
- job_name: 'vitaltrip-api'
metrics_path: '/metrics'
scrape_interval: 5s
static_configs:
- targets: ['api:3000']
- job_name: 'node-exporter'
static_configs:
- targets: ['node-exporter:9100']
- job_name: 'cadvisor'
static_configs:
- targets: ['cadvisor:8080']이제 Prometheus는 애플리케이션, 호스트, 컨테이너 세 곳에서 동시에 메트릭을 수집합니다.
Grafana 커뮤니티 대시보드
node-exporter와 cAdvisor는 사용 사례가 많은 exporter이기 때문에, Grafana 커뮤니티에서 이미 잘 만들어진 대시보드가 공개되어 있습니다. Grafana 대시보드에서 "Import" → ID 입력으로 바로 사용할 수 있습니다.
| 대시보드 | ID | 설명 |
|---|---|---|
| Node Exporter Full | 1860 | EC2 호스트 CPU/메모리/디스크/네트워크 |
| cAdvisor exporter | 14282 | 컨테이너별 CPU/메모리/네트워크 I/O |
직접 패널을 하나씩 구성하지 않아도, 커뮤니티 대시보드를 Import하면 즉시 호스트와 컨테이너 전체를 한눈에 볼 수 있습니다.
Grafana 대시보드 구성
Grafana에서는 Prometheus를 데이터 소스로 추가한 뒤, 필요한 패널을 구성했습니다.
1. 초당 요청 수
서버가 현재 어느 정도의 트래픽을 받고 있는지 보기 위한 패널입니다.
sum(rate(http_requests_total[1m]))API별로 나누어 보고 싶다면 route label을 기준으로 집계합니다.
sum by (route) (rate(http_requests_total[1m]))2. 상태 코드별 요청 수
에러율을 확인하기 위한 기본 패널입니다.
sum by (status_code) (rate(http_requests_total[1m]))부하테스트 중 5xx가 증가하면 서버 내부 예외, DB 연결 실패, 타임아웃 등을 의심할 수 있습니다.
3. p95 응답 시간
평균 응답 시간만 보면 일부 느린 요청이 가려질 수 있습니다. 그래서 p95를 함께 봐야 합니다.
histogram_quantile(
0.95,
sum(rate(http_request_duration_seconds_bucket[1m])) by (le, route)
)p95는 전체 요청 중 95%가 이 시간 안에 처리되었다는 의미입니다. 예를 들어 p95가 2초라면, 100개 요청 중 95개는 2초 이하로 처리되었다는 뜻입니다.
사용자 경험 관점에서는 평균보다 p95가 더 중요할 때가 많습니다. 평균은 괜찮아 보여도 일부 사용자가 계속 느린 응답을 경험할 수 있기 때문입니다.
4. API별 응답 시간 비교
어떤 API가 병목인지 찾기 위한 패널입니다.
histogram_quantile(
0.95,
sum(rate(http_request_duration_seconds_bucket[1m])) by (le, route, method)
)이 패널을 통해 로그인, 토큰 재발급, 사용자 조회 같은 인증 관련 API의 응답 시간이 다른 API보다 높게 나타나는지 확인할 수 있었습니다.
5. 프로세스 메모리 사용량
Node.js 프로세스 메모리 사용량을 확인하기 위한 패널입니다.
process_resident_memory_bytes부하테스트 중 메모리가 계속 증가한다면 메모리 누수나 요청 단위 객체 보관 문제를 의심할 수 있습니다.
모니터링을 하면서 알게 된 것
모니터링을 붙이기 전에는 부하테스트 결과를 보고 “서버가 느리다”고만 말할 수 있었습니다.
하지만 Prometheus와 Grafana를 붙이고 나서는 조금 더 구체적으로 볼 수 있었습니다.
- 요청량이 늘어나는 시점과 p95 응답 시간이 치솟는 시점을 비교할 수 있었습니다.
- 특정 인증 API의 응답 시간이 다른 API보다 크게 증가하는지 확인할 수 있었습니다.
- 에러율은 0%인데 응답 시간만 나빠지는 상황을 구분할 수 있었습니다.
- 성능 개선 전후의 변화를 같은 기준으로 비교할 수 있었습니다.
특히 “에러가 없다”와 “성능이 좋다”는 완전히 다른 문제라는 점을 체감했습니다.
이번 부하테스트에서도 에러율은 계속 0%였습니다. 하지만 최초 p95는 30.52초였습니다. 사용자는 에러 페이지를 보지 않더라도, 30초 동안 응답을 기다리면 서비스가 멈췄다고 느낄 가능성이 큽니다.
이런 문제를 발견하려면 반드시 응답 시간, p95, TPS 같은 지표를 함께 봐야 합니다.
개선 사례: 인증 API 병목 줄이기
모니터링과 부하테스트를 통해 인증 관련 흐름의 응답 시간이 높다는 점을 확인한 뒤, 다음과 같은 최적화를 진행했습니다.
1. bcrypt cost factor 조정
기존에는 비밀번호 해싱에 bcrypt cost factor 12를 사용하고 있었습니다.
const SALT_ROUNDS = 12;bcrypt는 의도적으로 느리게 동작하는 password hashing 알고리즘입니다. 비밀번호 저장에는 적합하지만, 요청량이 늘어날수록 CPU 비용이 크게 증가합니다.
부하테스트 환경에서 인증 API의 처리량을 개선하기 위해 cost factor를 12에서 10으로 조정했습니다.
const SALT_ROUNDS = 10;단, 이 작업은 보안과 성능 사이의 트레이드오프입니다. 비밀번호에는 여전히 bcrypt를 사용하되, 현재 서버 성능과 목표 처리량을 기준으로 적절한 cost를 선택해야 합니다.
2. Prisma DB 커넥션 풀 확장
Prisma의 MySQL connection limit을 기본값 수준에서 20으로 확장했습니다.
DATABASE_URL="mysql://user:password@host:3306/db?connection_limit=20"동시 요청이 늘어나면 DB 커넥션을 기다리는 시간이 병목이 될 수 있습니다. 커넥션 풀을 늘려 동시에 처리 가능한 DB 작업 수를 확장했습니다.
물론 connection limit을 무작정 키우는 것은 위험합니다. DB 서버의 max connection, CPU, 메모리, 쿼리 비용을 함께 봐야 합니다. 이번 경우에는 EC2와 MySQL 환경에서 부하테스트를 기준으로 20까지 늘려 성능 변화를 확인했습니다.
3. 누락된 refreshToken 해싱 비용 수정
auth.service.ts에서는 bcrypt cost를 조정했지만, users.service.ts의 updateRefreshToken 흐름에는 기존 cost가 남아 있었습니다.
인증 흐름에서는 로그인뿐 아니라 refresh token 저장도 자주 발생할 수 있습니다. 따라서 해당 부분도 동일하게 cost factor를 조정했습니다.
이 작업을 통해 인증 흐름 내부의 해싱 비용이 일관되게 관리되도록 수정했습니다.
4. DB 조회 select 최적화
기존에는 사용자 조회 시 전체 컬럼을 가져오는 방식이었습니다.
하지만 인증 흐름에서 필요한 필드는 제한적입니다. 예를 들어 로그인에서는 비밀번호 검증을 위해 id, email, password, role 정도만 필요합니다.
그래서 다음과 같이 필요한 필드만 선택하도록 변경했습니다.
const user = await this.prisma.user.findUnique({
where: { email },
select: {
id: true,
email: true,
name: true,
password: true,
role: true,
provider: true,
},
});적용한 조회 최적화는 다음과 같습니다.
| 함수 | Before | After |
|---|---|---|
findByEmailWithPassword | 전체 컬럼 조회 | id, email, name, password, role, provider |
findByIdWithRefreshToken | 전체 컬럼 조회 | id, email, role, refreshToken |
findByIdWithPassword | 전체 컬럼 조회 | id, password |
컬럼 수가 적을 때는 차이가 작아 보일 수 있지만, 인증 API처럼 자주 호출되는 경로에서는 불필요한 데이터 조회를 줄이는 것이 누적 비용을 낮추는 데 도움이 됩니다.
5. refreshToken 해싱 알고리즘 교체
가장 큰 개선 포인트 중 하나는 refreshToken 저장 방식이었습니다.
기존에는 refreshToken도 bcrypt로 해싱하고 비교했습니다.
const hashedRefreshToken = await bcrypt.hash(refreshToken, SALT_ROUNDS);
const isValid = await bcrypt.compare(refreshToken, user.refreshToken);하지만 refreshToken은 사용자가 직접 만든 짧고 예측 가능한 비밀번호가 아닙니다. 서버가 생성하고 서명한 JWT이며, 충분히 긴 bearer token입니다.
비밀번호는 사용자가 재사용하거나 짧게 만들 수 있기 때문에 slow hashing이 필요합니다. 반면 refreshToken은 서버가 생성한 고엔트로피 토큰이므로, 매 요청마다 bcrypt의 높은 CPU 비용을 지불하는 것은 과한 선택일 수 있다고 판단했습니다.
그래서 refreshToken은 SHA-256 digest로 저장하고, 비교 시에는 crypto.timingSafeEqual을 사용하도록 변경했습니다.
import { createHash, timingSafeEqual } from 'crypto';
function hashToken(token: string) {
return createHash('sha256').update(token).digest('hex');
}
function compareToken(token: string, hashedToken: string) {
const tokenBuffer = Buffer.from(hashToken(token), 'hex');
const hashedTokenBuffer = Buffer.from(hashedToken, 'hex');
if (tokenBuffer.length !== hashedTokenBuffer.length) {
return false;
}
return timingSafeEqual(tokenBuffer, hashedTokenBuffer);
}주의할 점은 이 방식을 비밀번호에 적용하면 안 된다는 것입니다. 비밀번호는 여전히 bcrypt, argon2, scrypt 같은 password hashing 알고리즘을 사용해야 합니다.
이번 변경은 refreshToken이 서버 생성 토큰이라는 특성을 고려한 최적화입니다.
개선 결과
최적화 후 같은 조건으로 부하테스트를 다시 진행했습니다.
| 단계 | p95 | avg | TPS |
|---|---|---|---|
| Before | 30.52s | 21.9s | 3.23/s |
| 1차 개선: bcrypt cost 조정 + 커넥션 풀 확장 | 19.23s | 13.84s | 4.96/s |
| 2차 개선: SHA-256 + select 최적화 | 15.63s | 10.54s | 6.33/s |
누적 개선 결과는 다음과 같습니다.
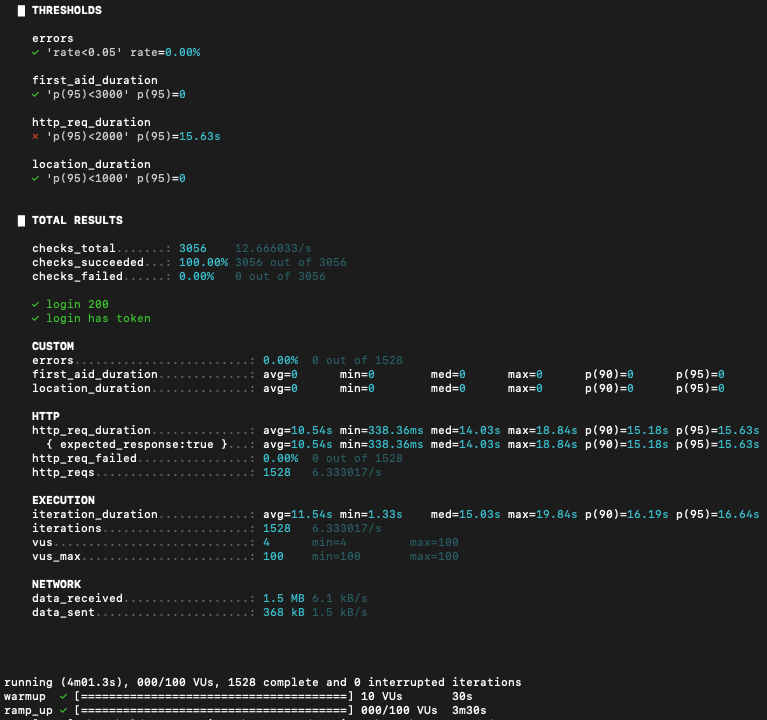
| 지표 | 개선 전 | 개선 후 | 변화 |
|---|---|---|---|
| p95 | 30.52s | 15.63s | 약 48.8% 감소 |
| avg | 21.9s | 10.54s | 약 51.8% 감소 |
| TPS | 3.23/s | 6.33/s | 약 95.9% 증가 |
| 에러율 | 0% | 0% | 유지 |
이번 개선의 핵심은 단순히 “코드를 빠르게 만들었다”가 아닙니다.
모니터링을 통해 병목을 관찰하고, 가설을 세우고, 하나씩 개선한 뒤, 다시 같은 조건으로 측정했다는 점이 중요했습니다.
성능 개선은 감으로 하는 작업이 아니라 측정 가능한 반복 과정이어야 한다는 것을 배웠습니다.
Grafana를 볼 때 주의한 점
처음 Grafana를 사용할 때는 대시보드에 숫자가 나오지 않거나, 요청을 보냈는데 request count가 0으로 보이는 경우가 있었습니다.
이럴 때는 보통 다음을 확인해야 합니다.
1. Prometheus target이 UP 상태인지
Prometheus의 Targets 화면에서 NestJS 서버가 UP인지 확인해야 합니다. DOWN이라면 Prometheus가 /metrics를 가져오지 못하고 있는 것입니다.
확인할 것:
- Prometheus 설정의 target 주소가 맞는가?
- Docker Compose 네트워크 이름이 맞는가?
- NestJS 서버에서
/metrics가 열려 있는가? - EC2 보안 그룹이나 방화벽에 막히지 않았는가?
2. Grafana time range가 맞는지
대시보드의 시간 범위가 “Last 5 minutes”인데, 요청을 10분 전에 보냈다면 데이터가 보이지 않을 수 있습니다.
부하테스트 중에는 보통 “Last 5 minutes” 또는 “Last 15 minutes” 정도로 두고 실시간 변화를 보는 것이 편했습니다.
3. PromQL의 rate 구간이 너무 짧지 않은지
아래처럼 rate(...[10s])를 사용하면 scrape interval과 맞지 않아 값이 튀거나 0처럼 보일 수 있습니다.
rate(http_requests_total[10s])처음에는 다음처럼 1분 정도로 보는 것이 안정적입니다.
rate(http_requests_total[1m])4. 실제로 인터셉터가 등록되어 있는지
/metrics는 열려 있지만 HTTP 요청 메트릭이 없다면, NestJS의 MetricsInterceptor가 전역으로 등록되지 않았을 수 있습니다.
기본 프로세스 메트릭과 커스텀 HTTP 메트릭은 별개입니다. HTTP 요청 수와 응답 시간을 보려면 요청 처리 흐름에서 직접 Counter와 Histogram을 기록해야 합니다.
마무리
이번 모니터링 구축을 통해 가장 크게 배운 것은 “운영 가능한 서버는 관찰 가능해야 한다”는 점입니다.
기능이 동작하는 서버와 운영 가능한 서버는 다릅니다.
기능이 동작하는 서버는 요청을 받으면 올바른 응답을 반환합니다. 운영 가능한 서버는 여기에 더해, 현재 상태를 설명할 수 있어야 합니다.
- 지금 얼마나 많은 요청을 받고 있는가?
- 어떤 API가 느린가?
- 에러가 늘고 있는가?
- 배포 이후 성능이 나빠졌는가?
- 병목이 CPU인지 DB인지 애플리케이션 로직인지 추정할 수 있는가?
Prometheus와 Grafana는 이 질문에 답하기 위한 기반을 만들어줬습니다.
또한 k6 부하테스트와 함께 사용했을 때 효과가 더 컸습니다. k6는 외부에서 본 사용자 경험을 보여주고, Grafana는 서버 내부 지표의 변화를 보여줍니다.
두 도구를 함께 사용하면 “느리다”에서 끝나지 않고 “왜 느린지”를 찾아갈 수 있습니다.