📚 목차
[Backend] NestJS로 구현하는 RAG 기반 AI API 아키텍처
GPT 기반으로 생성된 AI 답변을 그대로 믿어도 되는 걸까?
AI가 생성한 답변이 항상 정확하다고 보장할 수는 없다. AI 모델은 훈련 데이터에 기반하여 답변을 생성하기 때문에, 때로는 부정확하거나 모호한 정보를 제공할 수 있다. 따라서, AI가 생성한 답변을 검증하는 과정이 필요하다.
현재 개발하고 운영중인 VitalTrip 서비스는 전 세계 여행자들이 여행하면서 발생하는 응급 상황에 빠르게 대처할 수 있도록 돕는 AI 기반 여행 지원 서비스이다. 이 서비스에서는 RAG (Retrieval-Augmented Generation) 아키텍처를 활용하여, AI가 생성한 답변의 정확성을 높이고자 했다.
그래서 생명과 직결된 응급 상황에서 AI가 제공하는 정보의 신뢰성을 확보하기 위해, RAG 아키텍처를 도입하여 AI가 생성한 답변을 검증하는 시스템을 구축했다.
해당 서비스에서는 AI가 응급처치 방법과 국가별 응급 연락처를 함께 안내하는 API를 구현했다.
하지만 RAG를 도입하기 전에는 단순히 GPT API만 호출하는 방식에는 한계가 있었다.
사용자 증상 입력 -> GPT 호출 -> 응급처치 답변 생성
이 구조는 빠르게 만들 수 있지만, 응급처치처럼 신뢰도가 중요한 도메인에서는 위험할 수 있다.
LLM은 자연스러운 문장을 잘 생성하지만, 항상 공식 가이드라인에 기반한 답변을 보장하지는 않는다.
특히 응급상황에서는 그럴듯한 답변, 즉 Hallucination 보다 신뢰할 수 있는 근거 있는 답변이 더 중요하다.
그래서 VitalTrip 서비스에서는 GPT가 자체 학습 지식에만 의존하지 않도록, 미리 준비한 응급처치 가이드 문서를 검색한 뒤 그 내용을 함께 참고해 답변하도록 만들었다.
즉, 핵심 목표는 다음과 같았다.
사용자 증상 입력 -> 관련 응급처치 문서 검색 -> 검색된 문서를 GPT에 함께 전달 -> 근거 기반 응급처치 답변 생성
이를 위해 NestJS 기반 API 서버에 RAG 구조를 적용했다.
업로드한 설계 내용 기준으로, 지식베이스는 11개 증상 유형을 경중도별로 나눈 총 33개 Markdown 문서로 구성했고, 요청 시 사용자 증상 설명을 임베딩한 뒤 코사인 유사도로 관련 문서 상위 2개를 검색하는 흐름으로 설계했다.
전체 아키텍처
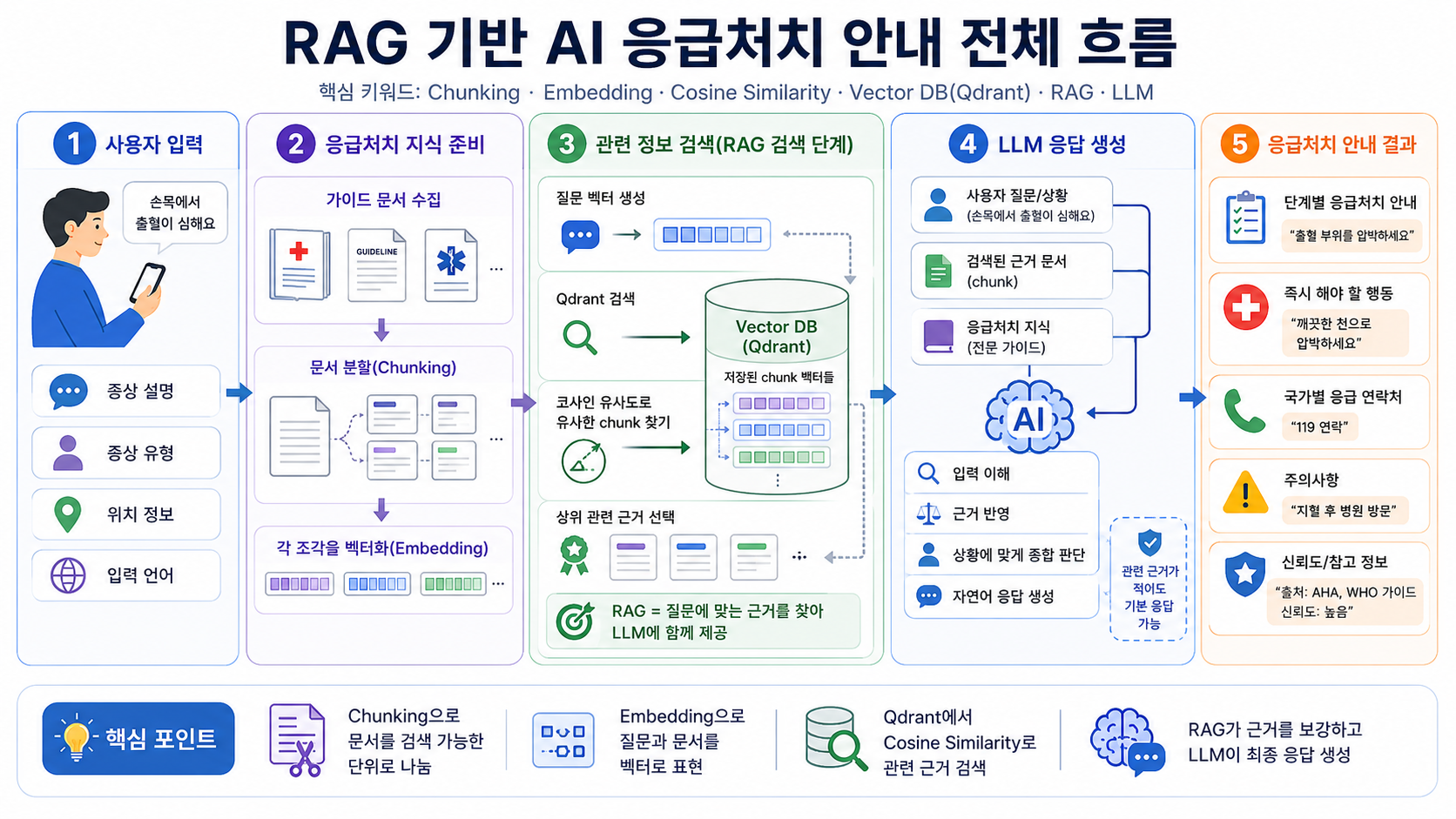
자세히 들어가기에 앞서, 전체 아키텍처를 살펴보자.
한 줄로 말하면, 사용자의 응급 상황 입력을 받아 → 관련 공식 가이드 문서를 검색하고 → 그 근거를 LLM에 넣어 → 단계별 응급처치 답변을 생성하는 RAG 기반 AI 응급처치 API 구조이다.
이 아키텍처는 RAG 기반 응급처치 안내 API 구조이다.
사용자가 증상, 위치, 언어 정보를 입력하면 서버는 먼저 질문을 임베딩 벡터로 변환하고, Qdrant Vector DB에서 의미적으로 가장 가까운 응급처치 가이드 문서 chunk를 검색한다.
이후 검색된 근거 문서를 LLM 프롬프트에 함께 주입하여, LLM이 공식 가이드 기반의 응급처치 안내를 생성하도록 한다.
이를 통해 GPT 단독 응답에서 발생할 수 있는 근거 부족과 할루시네이션 위험을 줄이고, 사용자에게 단계별 응급처치 방법, 현지 응급 연락처, 주의사항을 함께 제공한다.
LLM은 어떻게 답변을 만들고, RAG는 왜 필요한가?
먼저 LLM이 답변을 만드는 방식을 이해해야 RAG가 왜 필요한지도 명확해진다.
LLM은 사람이 문장을 이해하듯이 글자를 그대로 읽고 생각하는 것이 아니다.
입력 문장을 작은 단위로 쪼개고, 숫자 벡터로 바꾼 뒤, 문맥을 계산해서 다음에 올 가능성이 높은 토큰을 하나씩 예측한다.
전체 흐름은 다음과 같다.
-
- 문장 입력
-
- Tokenization
-
- Token ID 변환
-
- Embedding
-
- Transformer / Attention
-
- 다음 토큰 확률 예측
-
- Decoding 반복
-
- 최종 응답 생성
첫 번째, 문장을 토큰으로 쪼갠다.
사용자가 다음과 같이 입력했다고 해보자.
오른쪽 손목에서 출혈이 심합니다.
LLM은 이 문장을 그대로 이해하지 않고, 먼저 작은 조각으로 나눈다.
오른쪽 / 손목 / 에서 / 출혈 / 이 / 심합니다
이 작은 조각을 Token 이라고 한다.
한국어에서는 형태소, 단어 일부, 조사 등이 토큰 단위로 나뉠 수 있다.
영어도 마찬가지로 단어 전체가 하나의 토큰이 되기도 하고, 긴 단어는 여러 조각으로 나뉘기도 한다.
두 번째, 토큰을 숫자 ID로 바꾼다.
컴퓨터는 글자를 그대로 이해하지 못한다.
그래서 각 토큰은 사전에 정의된 숫자 ID로 변환된다.
예를 들면 이런 식이다.
오른쪽 = 18420
손목 = 9321
출혈 = 22157
심합니다 = 31002
이 숫자 자체가 의미를 가지는 것은 아니다.
단지 모델이 처리할 수 있도록 텍스트를 숫자로 바꾼 것이다.
세 번째, 숫자 ID를 의미 벡터로 바꾼다.
토큰 ID만으로는 의미를 알 수 없다.
그래서 모델은 각 토큰을 Embedding Vector으로 변환한다.
Embedding Vector는 단어의 의미적 특징을 숫자 배열로 표현한 것이다.
출혈 → [0.12, -0.03, 0.88, ...]
화상 → [0.09, -0.02, 0.81, ...]
학교 → [-0.44, 0.71, 0.10, ...]
이 벡터 공간에서는 의미가 비슷한 단어들이 가까운 위치에 놓인다.
예를 들어 출혈, 상처, 압박, 응급처치는 서로 가까운 의미 영역에 위치할 가능성이 높다.
반면 학교, 음악, 영화 같은 단어는 응급처치 문맥과는 상대적으로 멀리 위치한다.
RAG에서도 바로 이 임베딩 개념을 사용한다.
사용자의 증상 설명과 응급처치 문서를 같은 벡터 공간에 올려놓고, 서로 얼마나 가까운지 비교한다.
네 번째, 문맥을 계산한다.
같은 단어라도 문맥에 따라 의미가 달라질 수 있다.
예를 들어 다음 문장을 보자.
은행에 갔다.
여기서 은행은 돈을 맡기는 은행일 수도 있고, 강가의 은행일 수도 있다.
모델은 문장 안의 다른 단어들을 함께 보면서 어떤 의미가 더 적절한지 판단한다.
이때 핵심이 되는 구조가 Transformer의 Attention이다.
Attention은 쉽게 말하면 이런 질문을 계산하는 과정이다.
이 단어를 이해하려면 문장 안의 어떤 단어를 중요하게 봐야 할까?
응급처치 예시로 보면 다음과 같다.
오른쪽 손목에서 출혈이 심합니다.
모델은 출혈을 이해할 때 손목, 심합니다 같은 단어에 더 주목할 수 있다.
심합니다라는 표현이 있기 때문에 단순한 상처보다 심각한 출혈 상황으로 판단할 가능성이 높아진다.
즉, Attention은 단어 하나만 보는 것이 아니라,
문장 전체에서 중요한 관계를 찾아 문맥을 반영하는 역할을 한다.
다섯 번째, 다음에 올 토큰을 예측한다.
LLM은 문맥을 계산한 뒤, 다음에 올 가능성이 높은 토큰들을 확률로 예측한다.
예를 들어 다음 문장이 있다고 하자.
출혈이 심할 때는 상처 부위를
다음에 올 말로는 이런 후보들이 있을 수 있다.
압박하세요
씻으세요
움직이세요
기다리세요
모델은 각 후보에 대해 확률을 계산한다.
압박하세요: 72%
씻으세요: 12%
기다리세요: 8%
움직이세요: 3%
기타: 5%
그리고 설정된 방식에 따라 하나의 토큰을 선택한다.
응급처치 API에서는 답변이 너무 창의적으로 튀면 안 되기 때문에,
temperature를 낮게 설정해 더 안정적이고 예측 가능한 답변을 생성하도록 했다.
여섯 번째, 이 과정을 반복해 최종 문장을 만든다.
LLM은 한 번에 긴 답변 전체를 완성하는 것이 아니라,
다음 토큰을 하나 고르고, 다시 다음 토큰을 예측하는 과정을 반복한다.
출혈이 심할 때는 상처 부위를
출혈이 심할 때는 상처 부위를 깨끗한
출혈이 심할 때는 상처 부위를 깨끗한 천으로
출혈이 심할 때는 상처 부위를 깨끗한 천으로 압박하세요.
이렇게 토큰을 하나씩 이어 붙이며 최종 응답을 만든다.
정리하면 LLM의 핵심은 다음과 같다.
- LLM은 입력 문장을 token으로 쪼개고,
- 각 토큰을 embedding vector로 변환한 뒤,
- Transformer의 Attention 구조로 문맥을 계산하고,
- 다음에 올 토큰을 하나씩 예측하면서 답변을 생성한다.
그런데 여기서 중요한 문제가 있다.
LLM은 다음 토큰을 잘 예측하는 모델이지,
항상 최신 정보나 특정 서비스의 내부 지식, 공식 문서를 알고 있는 것은 아니다.
그래서 응급처치 API에서는 LLM에게 바로 답변을 맡기는 대신,
먼저 관련 공식 가이드 문서를 찾아서 함께 제공하는 구조가 필요했다.
이것이 RAG다.
- LLM 단독 응답 = 모델이 알고 있는 지식으로 답변 생성
- RAG 기반 응답 = 검색된 근거 문서를 함께 참고해 답변 생성
즉, RAG는 LLM의 답변 생성 능력에 외부 지식 검색을 결합하는 방식이다.
3. RAG 파이프라인 설계
서비스에서 RAG 파이프라인은 크게 네 단계로 구성했다.
문서 준비 -> Chunking -> Embedding -> Vector Store 적재 -> Cosine Similarity 기반 검색
문서 준비
응급처치 지식베이스는 Markdown 문서로 관리했다.
knowledge-base/documents/
bleeding-mild.md
bleeding-severe.md
bleeding-special.md
burn-mild.md
burn-severe.md
burn-special.md
...
문서는 증상별, 경중도별로 나누었다.
-mild.md
-severe.md
-special.md
이렇게 나눈 이유는 검색 단위를 명확히 하기 위해서다.
사용자가 "손목에서 피가 많이 난다"고 입력하면, bleeding-severe.md 같은 문서가 검색되는 것이 자연스럽다.
Chunking
Chunking은 긴 문서를 검색 가능한 작은 단위로 나누는 과정이다.
일반적인 RAG에서는 긴 PDF나 긴 문서를 일정한 토큰 수, 문단, 제목 기준으로 나눈다.
긴 문서
→ chunk 1
→ chunk 2
→ chunk 3
이번 프로젝트에서는 지식베이스 문서 수가 많지 않고, 이미 증상별/경중도별로 작게 분리되어 있었다.
그래서 별도의 복잡한 chunking 로직을 만들기보다, 각 Markdown 파일 하나를 하나의 chunk처럼 사용했다.
bleeding-severe.md = 하나의 검색 단위
burn-mild.md = 하나의 검색 단위
초기 MVP에서는 이 방식이 더 단순하고 관리하기 쉬웠다.
Embedding
각 문서는 Embedding 모델을 통해 벡터로 변환했다.
bleeding-severe.md
→ text-embedding-3-small
→ [0.12, -0.03, 0.88, ...]
사용자의 질문도 동일하게 벡터로 변환한다.
오른쪽 손목에서 출혈이 심합니다
→ text-embedding-3-small
→ [0.10, -0.04, 0.84, ...]
이렇게 문서와 질문을 같은 벡터 공간에 올려두면, 둘 사이의 의미적 유사도를 계산할 수 있다.
Vector Store
임베딩된 문서는 Vector Store에 저장된다.
개념적으로는 다음과 같은 구조다.
문서 텍스트 + 문서 메타데이터 + 임베딩 벡터
초기 구현에서는 외부 Vector DB를 바로 도입하지 않고,
사전에 생성한 vectors.json을 서버 시작 시 메모리에 로드했다.
pnpm seed:vectors
→ documents/*.md 임베딩
→ vectors.json 생성서버 시작
→ vectors.json 로드
→ documents[] 배열에 적재
이 방식은 문서 수가 적고 변경 빈도가 낮은 상황에서 단순하게 동작한다.
다만 데이터가 많아지면 Qdrant 같은 Vector DB로 확장할 수 있다.
초기 MVP
→ 인메모리 Vector Store확장 구조
→ Qdrant
→ 벡터 저장
→ 유사도 검색
→ top-K 문서 반환
즉, 현재 구조에서도 개념적으로는 Vector Store 역할을 하고 있고,
운영 규모가 커질 경우 Qdrant로 옮기기 쉬운 구조다.
Cosine Similarity
사용자 질문 벡터와 문서 벡터를 비교할 때는 코사인 유사도를 사용했다.
코사인 유사도는 두 벡터가 얼마나 비슷한 방향을 향하는지 계산한다.
값이 높다
→ 의미적으로 더 비슷하다값이 낮다
→ 의미적으로 덜 관련 있다
검색 흐름은 다음과 같다.
- 사용자 질문 임베딩 -> 모든 문서 벡터와 코사인 유사도 계산 -> 점수 기준 정렬 -> 상위 2개 문서 선택
예를 들어 사용자가 다음처럼 입력하면,
오른쪽 손목에서 출혈이 심합니다
검색 결과는 다음과 비슷할 수 있다.
1위: bleeding-severe.md
2위: bleeding-mild.md
그리고 이 문서들이 GPT 프롬프트에 함께 들어간다.
NestJS API 구조: 책임을 나누고 전체 흐름을 조합하기
RAG 기반 AI API는 단순히 OpenAI API 하나를 호출하는 구조가 아니다.
한 번의 요청 안에서 여러 작업이 함께 일어난다.
- 증상 입력 처리
- 위치 정보 처리
- 국가코드 확인
- 응급 연락처 조회
- 언어 감지
- RAG 문서 검색
- 프롬프트 조립
- LLM 호출
- 최종 응답 조합
이 로직을 하나의 파일에 모두 작성하면 유지보수가 어려워진다.
그래서 NestJS의 Service 구조를 활용해 책임을 나누었다.
| 서비스 | 역할 |
|---|---|
FirstAidService | 전체 요청 흐름 조합 |
GeocodingService | 위도/경도를 국가코드와 국가명으로 변환 |
EmergencyContactService | 국가코드 기반 응급 연락처 조회 |
VectorStoreService | 임베딩 문서 로드 및 유사도 검색 |
RagService | 사용자 증상과 관련된 문서 검색 |
OpenAiService | 언어 감지, 프롬프트 구성, GPT 호출 |
전체 요청 흐름은 다음과 같다.
POST /api/first-aid/advice
클라이언트 요청
{
symptomType,
symptomDetail,
latitude,
longitude
}
↓
FirstAidService
↓
1. 위치 기반 국가 정보 조회
2. 응급 연락처 조회
3. AI 응급처치 답변 생성
4. 최종 응답 조합FirstAidService는 세부 구현을 직접 처리하기보다,
각 서비스의 결과를 조합하는 오케스트레이션 역할을 한다.
async getAdvice(request: AdviceRequestDto) {
const countryInfo = await this.geocodingService.getCountryInfo(
request.latitude,
request.longitude,
);
const [emergencyContact, aiAdvice] = await Promise.all([
this.emergencyContactService.getContacts(countryInfo.countryCode),
this.openAiService.getAdvice(
request.symptomType,
request.symptomDetail,
countryInfo.countryCode,
),
]);
return {
...aiAdvice,
identificationResponse: {
...countryInfo,
emergencyContact,
},
};
}여기서 응급 연락처 조회와 AI 답변 생성은 병렬로 실행했다.
Promise.all([
응급 연락처 조회,
AI 답변 생성
])두 작업은 서로 직접적인 의존성이 없기 때문에 병렬 처리할 수 있다.
이렇게 하면 전체 응답 시간을 줄일 수 있다.
응답 생성 과정: RAG 검색 결과를 LLM 프롬프트에 주입하기
사용자 요청이 들어오면 AI 응답 생성 과정은 다음 순서로 진행된다.
-
- 입력 언어 감지
-
- 사용자 증상 설명 임베딩
-
- 관련 응급처치 문서 검색
-
- system prompt에 RAG 문서 삽입
-
- user prompt에 사용자 상황 삽입
-
- GPT-4o 호출
-
- JSON 응답 파싱
입력 언어 감지
사용자는 한국어, 영어, 일본어 등 다양한 언어로 증상을 입력할 수 있다.
오른쪽 손목에서 출혈이 심합니다
I have severe bleeding on my wrist
手首から出血しています
그래서 먼저 symptomDetail을 기반으로 응답 언어를 감지한다.
한국어 입력 → 한국어 응답
영어 입력 → 영어 응답
일본어 입력 → 일본어 응답
사용자는 자신의 언어로 입력하고,
같은 언어로 응급처치 안내를 받을 수 있다.
RAG 검색
다음으로 사용자의 증상 설명을 임베딩한다.
symptomDetail
→ embedding vector
그 다음 VectorStoreService에서 관련 문서를 검색한다.
query vector
→ documents[]와 코사인 유사도 비교
→ top-K 문서 반환
검색된 문서는 GPT가 참고할 근거 자료가 된다.
프롬프트 조립
프롬프트는 크게 두 부분으로 나누었다.
system prompt
→ AI의 역할, 응답 규칙, RAG 문서user prompt
→ 사용자 증상, 증상 유형, 국가코드, 응답 언어
예시는 다음과 같다.
system:
너는 응급처치 안내를 제공하는 AI다.
아래 응급처치 가이드 문서를 우선 참고해 답변하라.
[검색된 RAG 문서]
- bleeding-severe.md 내용
- bleeding-mild.md 내용
user:
responseLanguage: Korean
symptomType: BLEEDING
symptomDetail: 오른쪽 손목에서 출혈이 심합니다
countryCode: KR
additionalGuidance: 출혈 상황에서는 직접 압박, 응급 연락 안내를 우선 고려이 구조의 핵심은 GPT가 단독으로 답변하지 않게 만드는 것이다.
- GPT 단독 판단 -> 일반적인 답변 생성
- RAG 기반 판단 -> 검색된 응급처치 문서를 근거로 답변 생성
GPT 호출
응급처치 도메인에서는 답변의 안정성이 중요하다.
그래서 temperature를 낮게 설정했다.
const response = await this.openai.chat.completions.create({
model: 'gpt-4o',
temperature: 0.3,
response_format: { type: 'json_object' },
messages: [
{
role: 'system',
content: systemPromptWithRagContext,
},
{
role: 'user',
content: userPrompt,
},
],
});또한 API 응답으로 바로 사용하기 위해 JSON 형식 출력을 강제했다.
최종 응답은 다음과 같은 형태다.
{
"content": "출혈 부위를 깨끗한 천으로 직접 압박하세요...",
"summary": "심각한 출혈 응급처치",
"recommendedAction": "즉시 119에 연락하세요.",
"identificationResponse": {
"countryCode": "KR",
"countryName": "South Korea",
"emergencyContact": {
"police": "112",
"ambulance": "119",
"fire": "119"
}
},
"disclaimer": "AI 조언입니다. 실제 응급상황에서는 현지 응급기관의 도움을 받으세요.",
"confidence": 85,
"blogLinks": []
}마무리
VitalTrip 서비스에서 NestJS를 사용해 RAG 기반 AI 응급처치 API를 구현했다.
LLM은 입력 문장을 토큰으로 나누고, 임베딩 벡터로 변환한 뒤, Attention을 통해 문맥을 계산하고 다음 토큰을 반복적으로 예측하며 답변을 생성한다.
하지만 응급처치처럼 신뢰도가 중요한 도메인에서는 LLM의 생성 능력만으로는 부족하다.
그래서 사용자의 증상 설명을 임베딩하고, 응급처치 지식베이스에서 관련 문서를 검색한 뒤, 그 문서를 GPT의 system prompt에 함께 주입했다.
결과적으로 GPT가 자체 지식에만 의존하지 않고,
검색된 응급처치 가이드를 근거로 답변하도록 만들 수 있었다.
이번 구현을 통해 AI API의 핵심은 단순히 LLM을 호출하는 것이 아니라, LLM이 어떤 정보를 근거로 판단하게 만들 것인지 설계하는 것이라는 것을 다시 한 번 느꼈다.
RAG는 LLM의 자연어 생성 능력과 공식 지식베이스의 근거성을 연결하는 구조였고,
NestJS는 이 과정을 역할별로 분리해 안정적으로 구현하기 좋은 백엔드 프레임워크로 활용할 수 있었다.